
What is a Buffer Overflow Attack and How to Avoid it?
The Morris worm of 1988 was one of the experiences that deeply affected the industry. This incident demonstrated how quickly a worm could spread using a vulnerability known as buffer overflow or buffer overflow.
Almost 6,000 of the 60,000 computers connected to ARPANET, the pioneer of the Internet, were affected by the Morris worm. Although lessons were learned from this attack, such as software vendors taking security vulnerabilities seriously and setting up the first Computer Emergency Response Teams (CERT), it would not be the last attack to exploit a buffer overflow.
In 2001, Code Red worm, 359,000 people using Microsoft's IIS software Affected more than 1,000 computers. Code Red falsified web pages and attempted to stage denial of service attacks, including a web server in the White House.
Later in 2003, SQL Slammer worm has attacked more than 250,000 systems using Microsoft's SQL Server software. SQL Slammer affected routers, causing network traffic on the Internet to slow down drastically or even to a standstill. Code Red and SQL Slammer worms spread via buffer overflow vulnerabilities.
More than three decades later, we often encounter a buffer overflow vulnerability that still causes many negative consequences. Some various Although he accuses programming languages or their features of having an unsafe design, it seems that the main problem is the wrong use of these languages. To understand how a buffer overflow happens, we need to know a little about memory, especially the heap, and how software developers must manage memory when writing code.
What is a buffer and how does a buffer overflow occur?
A buffer is a block of memory that the operating system assigns for a software program. The program requests from the operating system the amount of memory required for the program to run correctly. In some programming languages such as Java, C#, Python, Go and Rust, memory management is automatically makes. In languages such as C and C++, programmers manually assign and free memory and check buffer lengths to ensure that memory limits are not exceeded.
However, programmers or coders who use the code library incorrectly can make mistakes. These errors lead to the emergence of many software vulnerabilities that are open to discovery and abuse. A properly designed program should determine the maximum memory size required to hold data and ensure that this size is not exceeded. A buffer overflow occurs when the program writes data beyond the allocated memory and into an adjacent block of memory that is reserved for other use or required by other processes.
There are two main types of buffer overflow: heap-sourced and stack-sourced. These expressions are used to tell the difference between a set and a heap.
Stack vs. set
Before a program is executed, the loader assigns that program a virtual address space containing the cluster and stack addresses. A cluster is a block of memory used for global variables and variables that are assigned (dynamically allocated) memory at runtime.
The software stack, which is like a stack of dishes stacked on top of each other, consists of frames that contain the local variables of a called function. Frames are pushed (added onto) the stack when functions are called, and removed from the stack when they return. In case of multiple threads, many stacks are created.
Compared to a cluster, heap is very fast, but there are two downsides to using heap. First, heap memory is limited, so placing large data structures on the stack more quickly exhausts available addresses. Secondly, each frame's lifetime is limited by being on the stack, meaning it is not possible to access data in a frame removed from the stack. When multiple functions need to access the same data, it is better to put the data in the cluster and add a cursor to the data (address) of these functions.
A buffer overflow can occur on the cluster or the heap. However, in this article, we focus on the more common type, stack-sourced buffer overflow.
Stack-sourced buffer overflow: Overwrite return address
Since the frames are stacked on top of each other each time a function is called, the return addresses also overlap the stack, telling the program where to continue execution when the called function is complete:
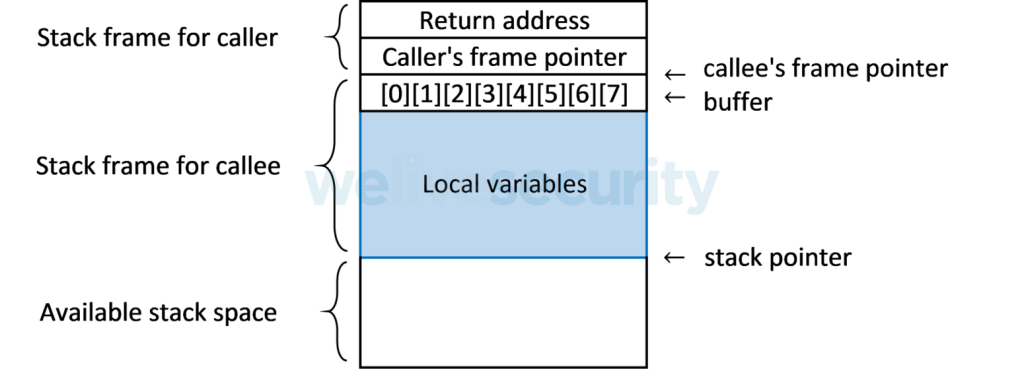
The return address is located near the buffers that hold the local variables. Therefore, a buffer overflow occurs when a malicious program succeeds in writing more data to a buffer than it can hold. Data that does not fit into the intended buffer 'overflows' to the return address and is overwritten.
In typical use of a vulnerable program, if a buffer overflow occurs, the new value of the often overwritten return address is not a valid memory location, meaning the program generates a memory allocation error and error recovery is required. When error recovery is not possible, the program may become unstable or even crash when the program overflow tries to return the stack frame from the replaced function. But cybercriminals take advantage of buffer overflows. By directly overwriting the return address with a valid memory location that points to their malicious code, in many cases they can create shells and take complete control of victim computers. For example Stuxnet worm a root used the buffer overflow vulnerability to create the shell.
Some exploit codes, after a malicious activity, intelligently repair the damage in the stack and recover the original return address. Attackers thus try to hide the return command violation and then ensure that the program continues to run as expected.
Example - Encoding hexadecimal characters as byte values
For software developers dealing with a buffer overflow discovered in 2021, we recommend the following code, written in C. CVE-2021-21748 the vulnerability in the ZTE MF971R LTE router tracked as This is a version written:
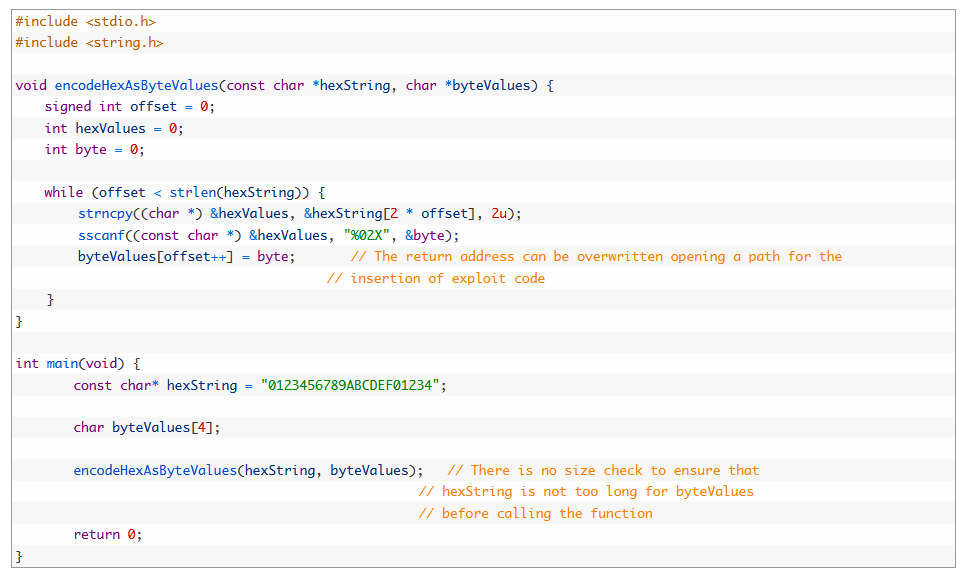
The program given above demonstrates the function that encodes a string of hexadecimal characters into a format with half the memory requirement. The two characters can exist as actual byte values (hexadecimal digits), so that the '0' and '1' characters, represented by byte values of 30 and 31, respectively, can be represented as a byte value of 01. This functionality was used as part of the ZTE router's handling of passwords.
As noted in the comments to the code, the 21 character hexString is too large for a buffer of byteValues with only 4 characters (although it can accept up to 8 characters in encoded form) and there is no way to be sure that encodeHexAsByteValues will not cause a buffer overflow.
Protection from buffer overflow attacks
Modern compilers and operating systems, as well as software programmers who develop careful programming and tests, implement various mechanisms to make buffer overflow attacks more difficult. Taking Linux's GCC compiler driver as an example to prevent abuse of buffer overflow We can mention two mechanisms used: heap randomization and heap corruption detection.
Stack randomization
In a way, the success of buffer overflow attacks relies on knowing the current memory location that points to the exploit code. In the past, stack locations were often in a single format, as the same combinations of programs and operating system versions had the same stack address. For this reason, attackers could manage a single attack to attack the same program-operating system combination, like a single biological virus strain.
Stack randomization allocates a random space to the stack at the start of program execution. This does not mean that the space will be used by the program, but it does ensure that the program has different stack addresses on each execution.
However, a determined attacker can overcome heap randomization by repeatedly trying different addresses. One technique is to use a long string of NOP (no operation) instructions at the beginning of the exploit code that only increments the program counter. In this case, instead of guessing the exact address at the start of the exploit code, the attacker simply has to guess the address of any of the many NOP instructions. When the program jumps to one of these NOP instructions, it is called a "NOP sled" because it continues to scroll through the rest of the NOP instructions until the actual start of the exploit code. The Morris worm, for example, started with 400 NOP instructions.
There are many techniques called randomization of the address space layout. The purpose of these techniques is to ensure that other parts of a program, such as program code, library code, global variables, and set data, have different memory addresses each time the program runs.
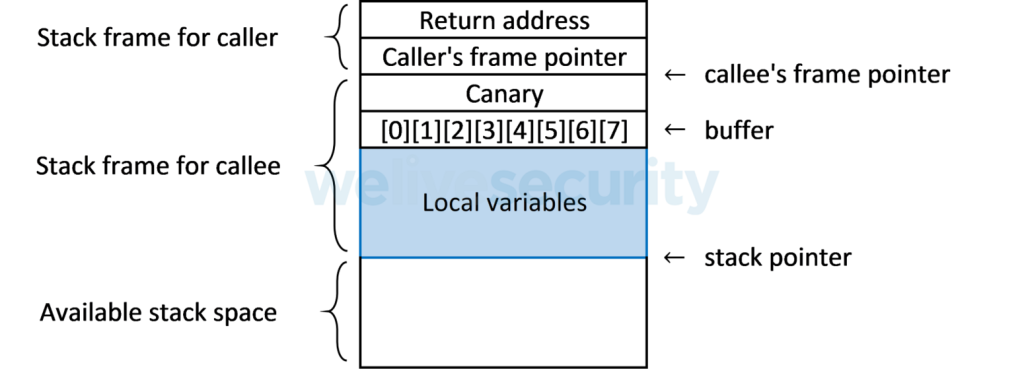
Stack corruption detection
Another method of preventing a buffer overflow attack is to detect when the stack is corrupted. A common mechanism known as the stack guard places a random canary value, or guard value, between the stack frame's local buffers and the rest of the stack. This way, before returning from a function, the program can check the status of the canary value and call an error routine if a buffer overflow has changed the canary value.
Final advice
As buffer overflow vulnerabilities continue to be discovered and fixed, the best advice is to have a solid policy of patching all applications and code libraries with the highest priority. In addition to security solutions that can detect exploit codes, by keeping the policy constantly up to date, strong protection can be created against attackers who want to exploit buffer overflows.
Source: https://www.eset.com/tr/blog/arabellek-tasmasi-saldirisi-nedir-ve-nasil-onlenir/
Sign up for the e-mail list to be informed about the developments in the cyber world and to be informed about the weekly newsletter.

